CompTIA DY0-001유효한시험자료, DY0-001 100%시험패스덤프자료
Wiki Article
그 외, ExamPassdump DY0-001 시험 문제집 일부가 지금은 무료입니다: https://drive.google.com/open?id=1nc7fRIkGmEQ_enor6e3haigvwOI9w8x1
ExamPassdump의CompTIA DY0-001교육 자료는 고객들에게 높게 평가 되어 왔습니다. 그리고 이미 많은 분들이 구매하셨고CompTIA DY0-001시험에서 패스하여 검증된 자료임을 확신 합니다. CompTIA DY0-001시험을 패스하여 자격증을 취득하면IT 직종에 종사하고 계신 고객님의 성공을 위한 중요한 요소들 중의 하나가 될 것이라는 것을 잘 알고 있음으로 더욱 믿음직스러운 덤프로 거듭나기 위해 최선을 다해드리겠습니다.
CompTIA DY0-001 시험요강:
| 주제 | 소개 |
|---|---|
| 주제 1 |
|
| 주제 2 |
|
| 주제 3 |
|
| 주제 4 |
|
| 주제 5 |
|
DY0-001 100%시험패스 덤프자료, DY0-001최신 업데이트 시험대비자료
CompTIA인증 DY0-001시험을 패스하여 자격증을 취득하는게 꿈이라구요? ExamPassdump에서 고객님의CompTIA인증 DY0-001시험패스꿈을 이루어지게 지켜드립니다. ExamPassdump의 CompTIA인증 DY0-001덤프는 가장 최신시험에 대비하여 만들어진 공부자료로서 시험패스는 한방에 끝내줍니다.
최신 CompTIA Data+ DY0-001 무료샘플문제 (Q26-Q31):
질문 # 26
Which of the following is best solved with graph theory?
- A. Fraud detection
- B. Traveling salesman
- C. One-armed bandit
- D. Optical character recognition
정답:B
설명:
The traveling-salesman problem is a prototypical graph theory challenge, finding the shortest tour through a graph's nodes, whereas the other tasks rely on different domains (OCR on image processing, fraud detection often on statistical/anomaly methods, bandit problems on sequential decision theory).
질문 # 27
A data scientist needs to determine whether product sales are impacted by other contributing factors. The client has provided the data scientist with sales and other variables in the data set.
The data scientist decides to test potential models that include other information.
INSTRUCTIONS
Part 1
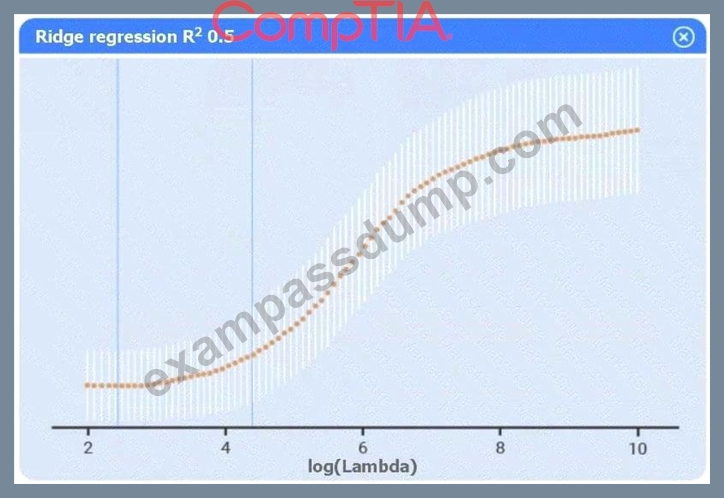
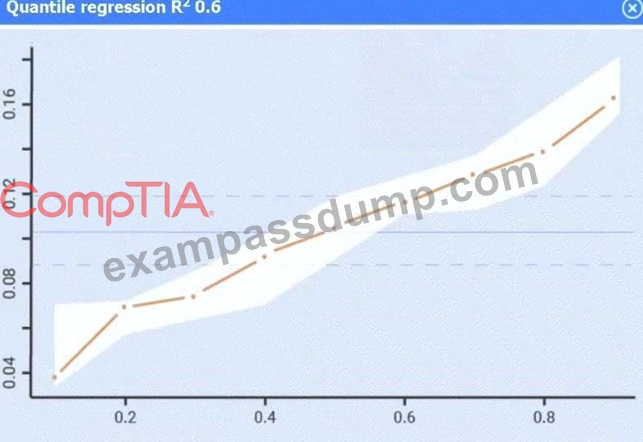
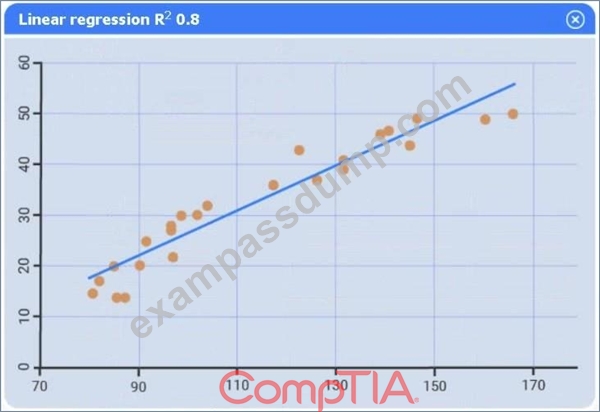
Use the information provided in the table to select the appropriate regression model.
Part 2
Review the summary output and variable table to determine which variable is statistically significant.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.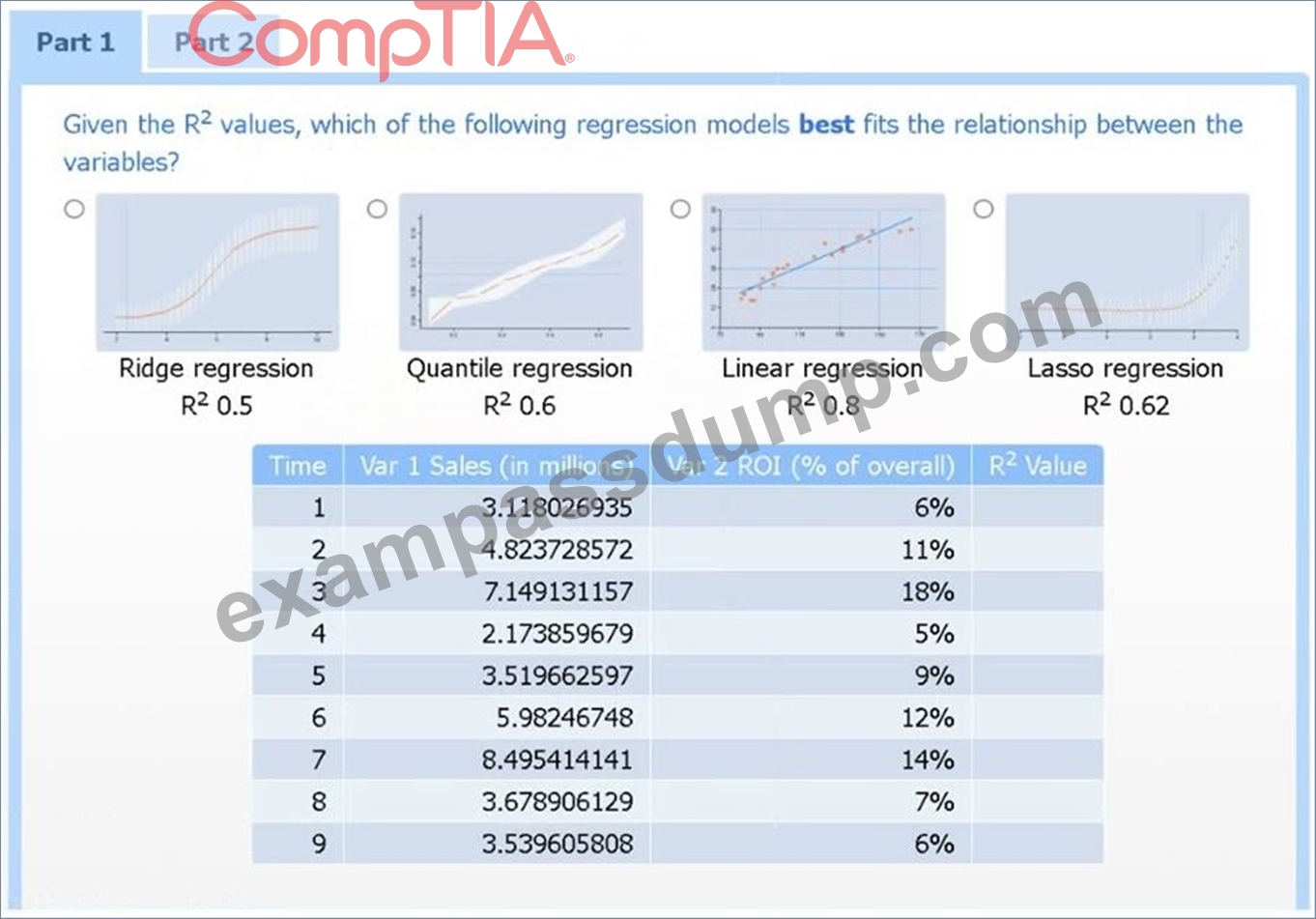
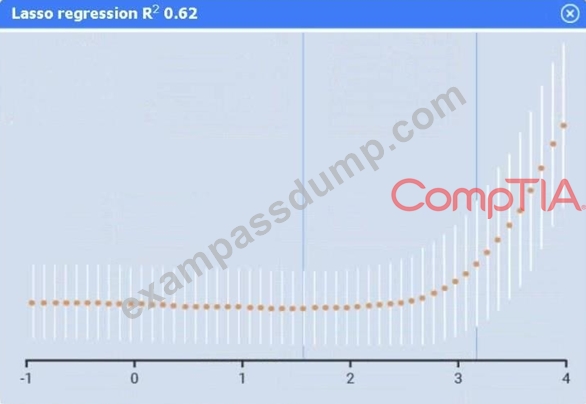
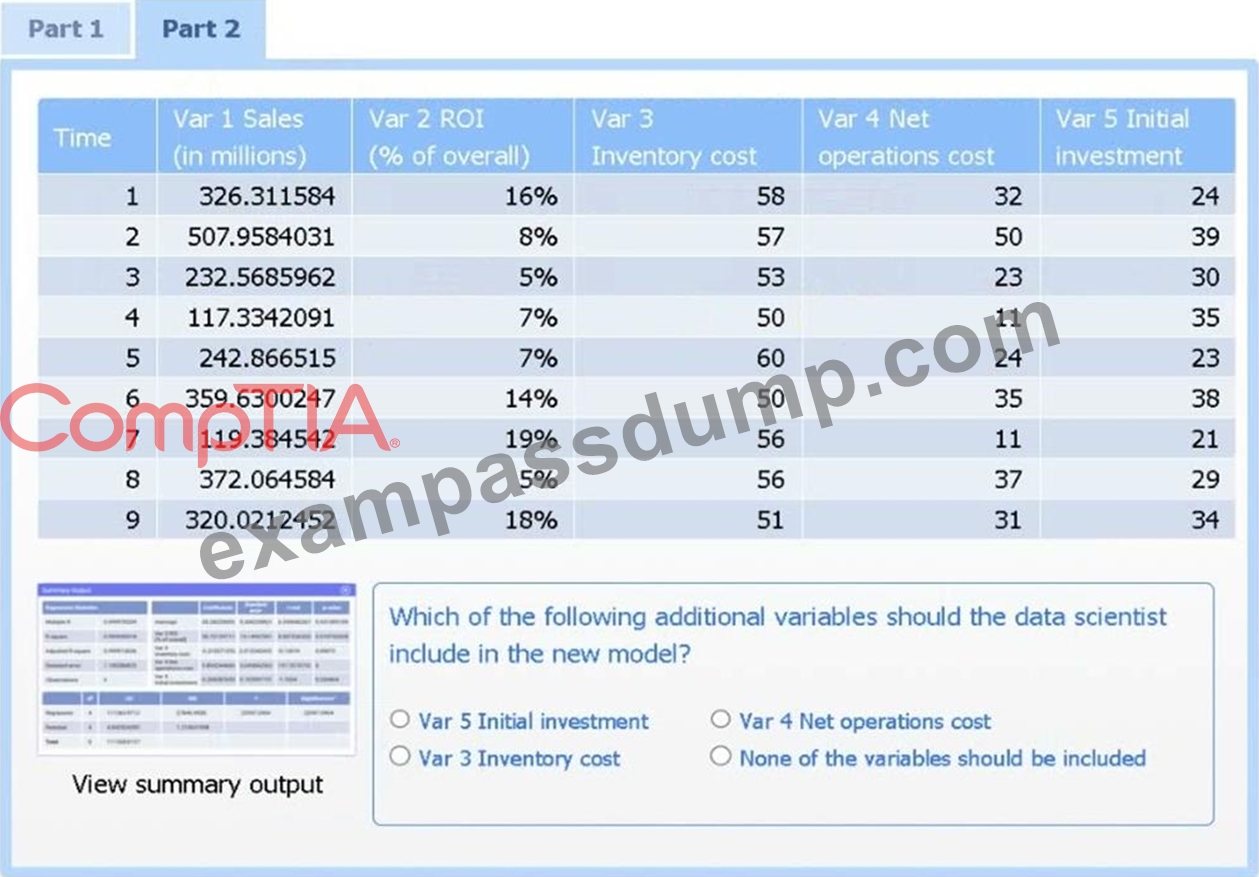
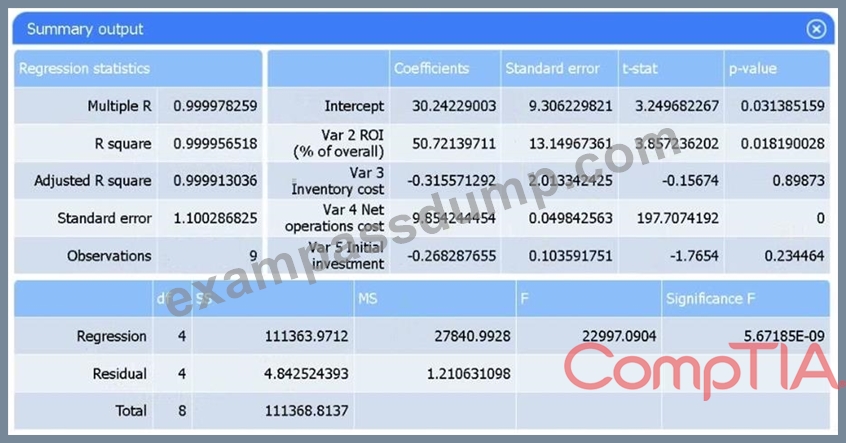
정답:
설명:
See explanation below.
Explanation:
Part 1
Linear regression.
Of the four models, linear regression has the highest R² (0.8), indicating it explains the greatest proportion of variance in sales.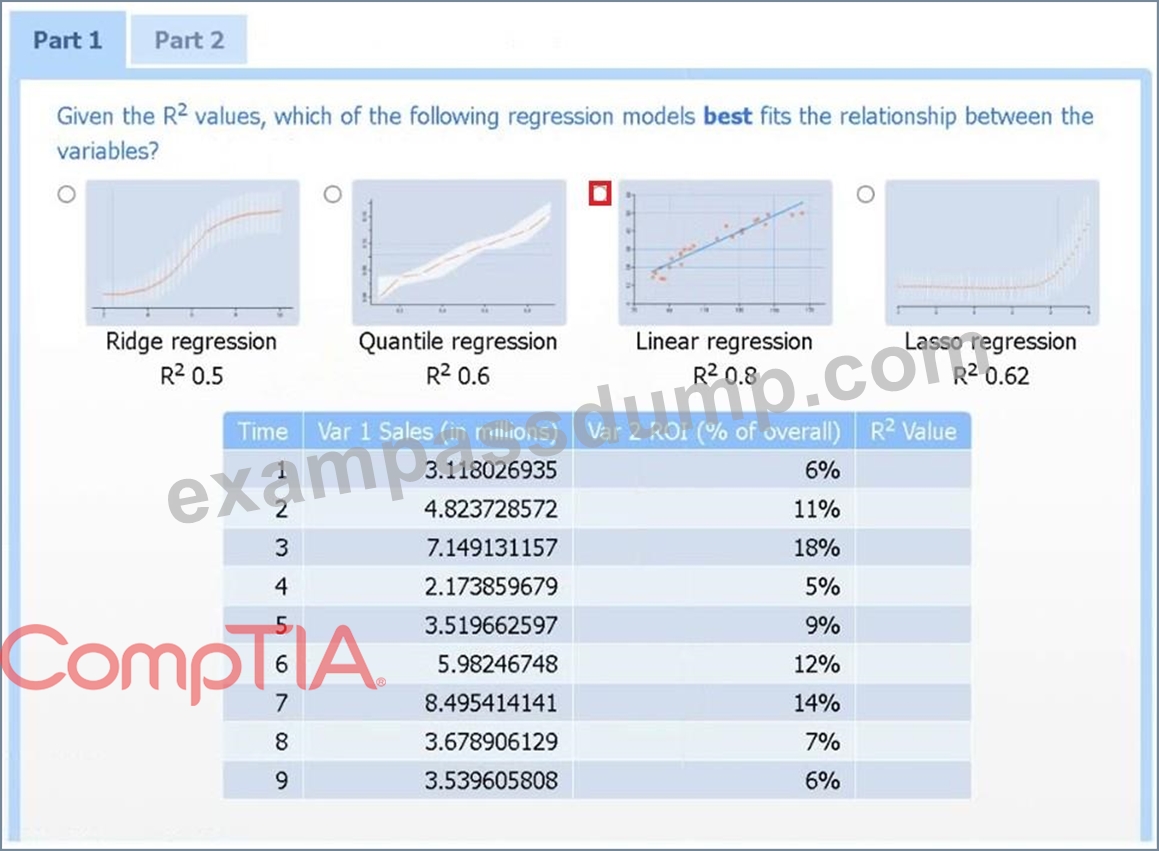
Part 2
Var 4 - Net operations cost.
Net operations cost has a p-value of essentially 0 (far below 0.05), indicating it is the only additional predictor statistically significant in explaining sales. Neither inventory cost (p#0.90) nor initial investment (p#0.23) reach significance.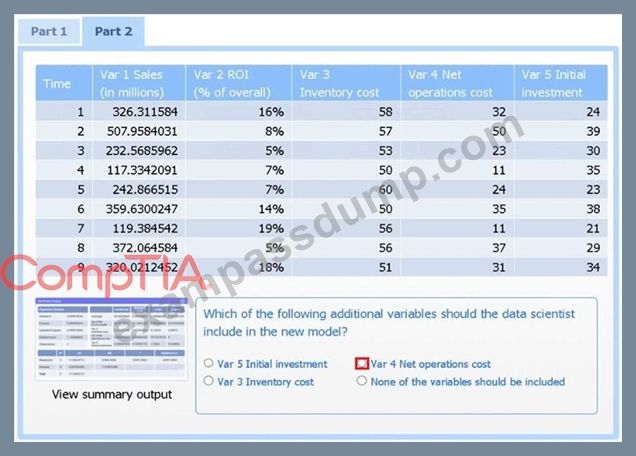
질문 # 28
A data scientist is building a forecasting model for the price of copper. The only input in this model is the daily price of copper for the last ten years. Which of the following forecasting techniques is the most appropriate for the data scientist to use?
- A. Autoregressive
- B. Moving average
- C. Dynamic time warping
- D. Relative strength
정답:A
설명:
An autoregressive model uses past values of the series itself (here, historical daily copper prices) as predictors for future values, making it the most suitable technique when only the time‐series history is available.
질문 # 29
Which of the following techniques enables automation and iteration of code releases?
- A. Virtualization
- B. Code isolation
- C. CI/CD
- D. Markdown
정답:C
설명:
Continuous Integration/Continuous Deployment pipelines automate the building, testing, and delivery of code, enabling rapid, repeatable, and iterative releases with minimal manual intervention.
질문 # 30
A data scientist wants to digitize historical hard copies of documents. Which of the following is the best method for this task?
- A. Semantic segmentation
- B. Latent semantic analysis
- C. Word2vec
- D. Optical character recognition
정답:D
설명:
# Optical Character Recognition (OCR) is the process of converting scanned images or hard copy text into machine-encoded text. It is the standard technique for digitizing printed or handwritten content.
Why the other options are incorrect:
* A: Word2vec is for generating word embeddings from digital text.
* C: Latent Semantic Analysis analyzes semantic structure of existing digital documents.
* D: Semantic segmentation is used in image processing for pixel-wise classification - not text extraction.
Official References:
* CompTIA DataX (DY0-001) Official Study Guide - Section 6.3:"OCR converts scanned physical documents into text files that can be searched, analyzed, or stored digitally."
* Practical NLP Applications, Chapter 2:"OCR is a prerequisite for turning printed or written material into structured data suitable for text analytics."
-
질문 # 31
......
CompTIA DY0-001 인증시험 최신버전덤프만 마련하시면CompTIA DY0-001시험패스는 바로 눈앞에 있습니다. 주문하시면 바로 사이트에서 pdf파일을 다운받을수 있습니다. CompTIA DY0-001 덤프의 pdf버전은 인쇄 가능한 버전이라 공부하기도 편합니다. CompTIA DY0-001 덤프샘플문제를 다운받은후 굳게 믿고 주문해보세요. 궁금한 점이 있으시면 온라인서비스나 메일로 상담받으시면 됩니다.
DY0-001 100%시험패스 덤프자료: https://www.exampassdump.com/DY0-001_valid-braindumps.html
- DY0-001자격증참고서 ???? DY0-001최신 업데이트버전 덤프 ⚖ DY0-001 100%시험패스 덤프자료 ???? ➽ www.exampassdump.com ????을(를) 열고【 DY0-001 】를 입력하고 무료 다운로드를 받으십시오DY0-001 100%시험패스 덤프자료
- DY0-001유효한 시험자료 최신인기 인증 시험덤프샘플문제 ???? 무료 다운로드를 위해 지금➡ www.itdumpskr.com ️⬅️에서{ DY0-001 }검색DY0-001시험패스 덤프공부자료
- 높은 적중율을 자랑하는 DY0-001유효한 시험자료 인증시험 ???? [ kr.fast2test.com ]을(를) 열고{ DY0-001 }를 입력하고 무료 다운로드를 받으십시오DY0-001시험대비 인증공부
- 높은 적중율을 자랑하는 DY0-001유효한 시험자료 덤프로 CompTIA DataAI Certification Exam 시험도전 ???? 무료 다운로드를 위해▶ DY0-001 ◀를 검색하려면《 www.itdumpskr.com 》을(를) 입력하십시오DY0-001최신 업데이트버전 시험자료
- 최신 DY0-001유효한 시험자료 인증시험 인기 덤프문제 ???? ➤ www.dumptop.com ⮘웹사이트에서✔ DY0-001 ️✔️를 열고 검색하여 무료 다운로드DY0-001자격증참고서
- DY0-001유효한 시험자료 100%시험패스 인증덤프공부 ???? 오픈 웹 사이트( www.itdumpskr.com )검색▶ DY0-001 ◀무료 다운로드DY0-001최신버전 덤프공부
- DY0-001최신 업데이트버전 덤프 ???? DY0-001최신 업데이트버전 시험자료 ???? DY0-001유효한 최신덤프자료 ???? ➤ www.dumptop.com ⮘에서“ DY0-001 ”를 검색하고 무료 다운로드 받기DY0-001최신 시험 최신 덤프
- DY0-001유효한 시험자료 최신인기 인증 시험덤프샘플문제 ???? ✔ www.itdumpskr.com ️✔️에서 검색만 하면「 DY0-001 」를 무료로 다운로드할 수 있습니다DY0-001최신버전 덤프공부
- DY0-001시험자료 ???? DY0-001퍼펙트 덤프 샘플문제 다운 ???? DY0-001유효한 최신덤프자료 ???? 무료로 다운로드하려면▷ www.koreadumps.com ◁로 이동하여《 DY0-001 》를 검색하십시오DY0-001시험난이도
- DY0-001시험난이도 ???? DY0-001 100%시험패스 덤프자료 ???? DY0-001최신 시험 최신 덤프 ???? ⇛ www.itdumpskr.com ⇚을(를) 열고[ DY0-001 ]를 입력하고 무료 다운로드를 받으십시오DY0-001 100%시험패스 덤프자료
- 최신 DY0-001유효한 시험자료 인증시험 인기 덤프문제 ???? ➠ www.exampassdump.com ????을(를) 열고☀ DY0-001 ️☀️를 입력하고 무료 다운로드를 받으십시오DY0-001 100%시험패스 덤프자료
- www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, webcastlist.com, lealhtv440571.onzeblog.com, www.stes.tyc.edu.tw, bookmark-search.com, fayvrrr109672.bloggosite.com, schoolido.lu, atmsafiulla.com, www.stes.tyc.edu.tw, Disposable vapes
그리고 ExamPassdump DY0-001 시험 문제집의 전체 버전을 클라우드 저장소에서 다운로드할 수 있습니다: https://drive.google.com/open?id=1nc7fRIkGmEQ_enor6e3haigvwOI9w8x1
Report this wiki page